|
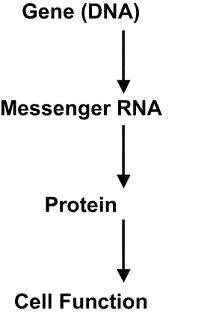
DNA controls cell function; RNA is synthesized from a gene on the DNA template in the nucleus. The protein is then synthesized from RNA to carry out cell function. |
|
|
|
|
Click here for a movie on "Transcription".
|
MOLECULAR & CELLULAR
NEUROBIOLOGY
Master Course Cognitive Neuroscience - Radboud
University, Nijmegen
|
|
|
|
Chapter 2: Cells and within cells |
|
|
Transcription: DNA → RNA
|
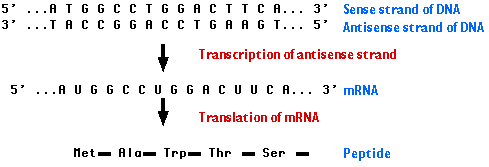
The central dogma of molecular biology is now well established, namely, DNA produces RNA, which in turn produces a polypeptide that makes up the protein that provides the cell structure and performs the functions of the cell (Figures below). The genetic information inherited by each individual is encoded by the sequences of the bases of the DNA in the genome (the genotype), which is translated into proteins and provides the recognizable characteristics of the individual (the phenotype), such as height and weight. For DNA to produce proteins, it must first go through the intermediary step of RNA. DNA, the double-stranded molecule, unwinds to give a single-stranded RNA molecule that serves as the template for protein. This process, since it goes from one nucleic acid to another nucleic acid, is referred to as transcription. This is a key regulatory step in the old process of replicating and maintaining life. There are several aspects in the regulation of transcription, as indicated in the table below. The process of transcription is initiated by attachment of the enzyme RNA polymerase to specific recognition sites where the DNA is double-stranded but, upon activation by the enzyme, the strands selectively unwind and separate. The RNA polymerase copies the DNA sequence to a similar molecule called messenger RNA (mRNA). mRNA travels out into the cytoplasm.The binding site for the RNA polymerase II is always on the 5′ end of the gene and travels on a single-stranded DNA towards the 3′ end. Messenger RNA in addition to being single-stranded also differs from DNA in that the deoxyribose sugar found in DNA is replaced by ribose. Furthermore, uracil (U) replaces T and, like T, U pairs exclusively with A. The mRNA transcribed from DNA is usually referred to as the primary transcript and is a complementary copy of the DNA.The DNA stays inside the nucleus, while the mRNA exits the nucleus but, prior to transport, undergoes extensive posttranscriptional processing primarily through the three following main events: (1) the addition of the methylated guanosine to the 5′ end, referred to as a CAP, which is important for the initiation of translation; (2) addition of a long tail of repeated adenine nucleotides called the polyadenine tail to the 3′ region of the mRNA, which is essential for stability as it passes out into the cytoplasm to serve as a template for protein synthesis; (3) the primary transcript, which contains introns and exons, undergoes a specific splicing process whereby the introns are removed and exons are properly respliced together prior to exit from the nucleus. It is then referred to as the mature mRNA. The exons of the 3′ end do not code for proteins but for signals that terminate translation and direct the addition of the polyadenine tail. The mature mRNA exits the nucleus through nuclear pores and, upon entering the cytoplasm, attaches to ribosomal RNA. The majority of genes are expressed as the proteins they encode. The process thus occurs in two steps:
Taken together, they make up the "central dogma" of biology: DNA → RNA → protein. Here is an overview: |
|
|||||
| Click here for a movie on "Transcription".
|
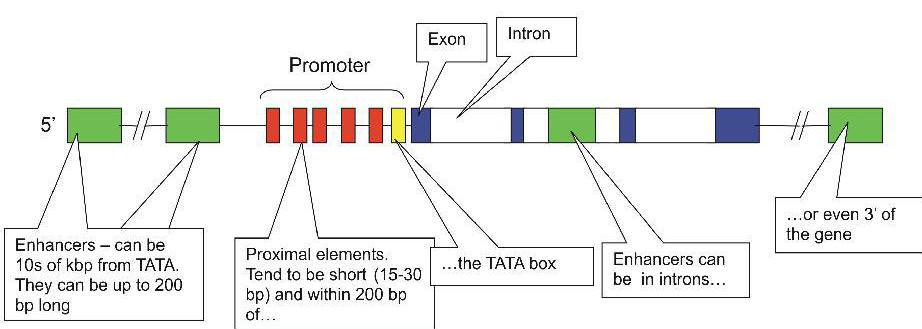
Regulation of gene transcription
Transcription start site
|
|
|
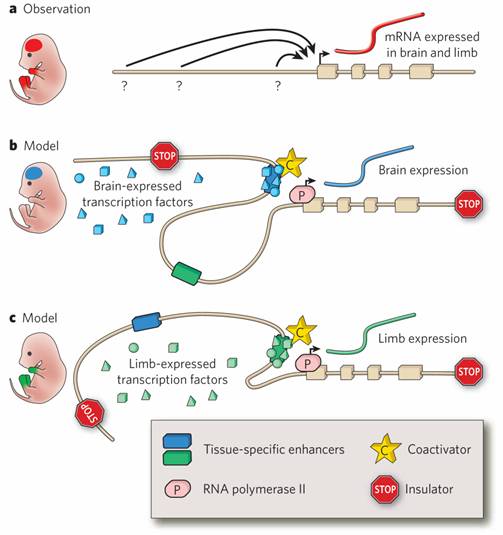
Figure 1. Gene regulation by distant-acting enhancers. a, For many genes, the regulatory information embedded in the promoter is insufficient to drive the complex expression pattern observed at the messenger RNA level. For example, a gene could be expressed both in the brain and in the limbs during embryonic development (red), even if the promoter by itself is not active in either of these structures, suggesting that appropriate expression depends on additional sequences that are distant-acting and cis-regulatory. However, defining the genomic locations of such regulatory elements (question marks) and their activities in time and space (arrows) is a major challenge. b, c, Tissue-specific enhancers are thought to contain combinations of binding sites for different transcription factors. Only when all required transcription factors are present in a tissue does the enhancer become active: it binds to transcriptional coactivators, relocates into physical proximity with the gene promoter (through a looping mechanism) and activates transcription by RNA polymerase II. In any given tissue, only a subset of enhancers is active, as schematically shown in b and c for the example gene pictured in a, whose expression is controlled by two separate enhancers with brain-specific and limb-specific activities. Insulator elements prevent enhancer–promoter interactions and can thus restrict the activity of enhancers to defined chromatin domains. In addition to activation by enhancers, negative regulatory elements (including repressors and silencers) can contribute to transcriptional regulation. |
SilencersSilencers are control regions of DNA that, like enhancers, may be located thousands of base pairs away from the gene they control. However, when transcription factors bind to them, expression of the gene they control is repressed. InsulatorsEnhancers can turn on promoters of genes located thousands of base pairs away. What is to prevent an enhancer from inappropriately binding to and activating the promoter of some other gene in the same region of the chromosome? One answer: an insulator. Insulators are:
Their function is to prevent a gene from being influenced by the activation (or repression) of its neighbors.
|