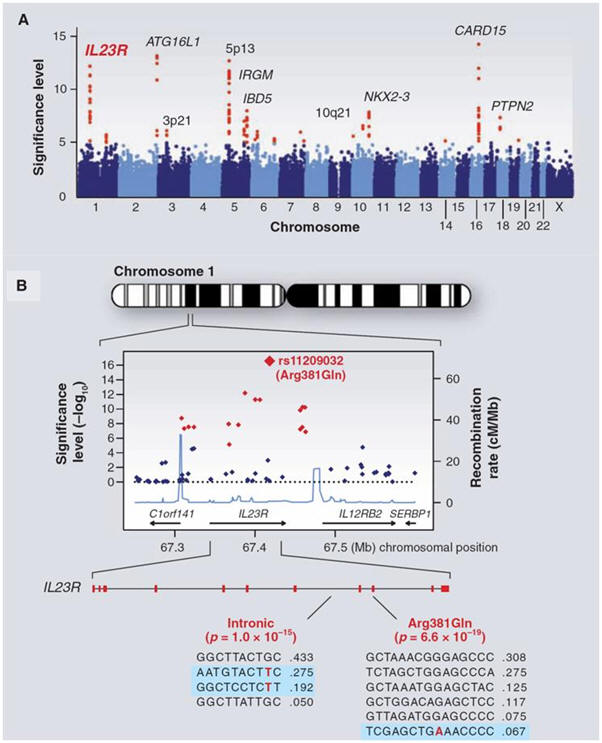
|
Various
lessons have already emerged from genetic mapping by GWAS:
1.
GWAS work. Before 2006, only about two dozen reproducible
associations had been discovered. By early 2008,
more than 150 relationships were identified between common SNPs
and disease traits. In most diseases studied, GWAS
have revealed multiple independent loci, although some traits
have not yet yielded associations that meet stringent thresholds
(e.g., hypertension). It is not clear whether this reflects
inadequate sample size, phenotypic definition, or a different
genetic architecture.
2.
Effect sizes for common variants are typically modest.
In a few cases, common variants with effects of a
factor of 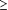 2
per allele have been found, e.g. APOE4 in Alzheimer's
disease. In the vast majority of cases,
however, the estimated effects are much smaller—mostly
increases in risk by a factor of 1.1 to 1.5 per associated allele. 2
per allele have been found, e.g. APOE4 in Alzheimer's
disease. In the vast majority of cases,
however, the estimated effects are much smaller—mostly
increases in risk by a factor of 1.1 to 1.5 per associated allele.
3.
The power to detect associations has been low. Given the effect
sizes now known to exist, and the need to exceed stringent
statistical thresholds, the first wave of GWAS provided low
power to discover disease-causing loci. For example,
achieving 90% power to detect an allele with 20% frequency
and a factor of 1.2 effect at a statistical significance of
10–8 requires 8600 samples. Thus, although it is unlikely
that common alleles of large effect have been missed, GWAS
of hundreds to several thousand cases have necessarily
identified only a fraction of the loci that can be found with
larger sample sizes. This prediction has been empirically
confirmed in type 2 diabetes, serum lipids, Crohn's disease, and height.
Increasing the power by pooling the samples to perform
meta-analysis and replication genotyping has increased this
yield to more than 100 replicated loci for these four conditions.
4.
Association signals have identified small regions for study
but have not yet identified causal genes and mutations. Genetic
mapping is a double-edged sword: local correlation of genetic
variants facilitates the initial identification of a region
but makes it difficult to distinguish causal mutation(s); luckily,
whereas family-based linkage methods typically yield regions
of 2 to 10 Mb in span, GWAS typically yield more manageable
regions of 10 to 100 kb. These regions have yet to be scrutinized
by fine-mapping and resequencing to identify the
specific gene and variants responsible. Even when
a locus is identified by SNP association, the causal
mutation itself need not be a SNP. For example, the
IRGM gene was associated with Crohn's disease
on the basis of GWAS. Subsequent study suggests that the
causal mutation is a deletion upstream of the
promoter affecting tissue-specific expression.
5.
A single locus can contain multiple independent common
risk variants, e.g. intensive study has already identified
seven independent alleles at 8q24 for prostate cancer
and two at IL23R for Crohn's disease. Multiple distinct
alleles with different frequencies and risk ratios may
well be the rule.
6.
A single locus can harbor both common variants of weak
effect and rare variants of large effect. In recent
GWAS, studies of common SNPs enabled the
identification of 19 loci as influencing low- or
high-density lipoprotein (LDL, HDL) or triglycerides. Nine of
these 19 were already known to carry rare
Mendelian mutations with large effects, such as the loci for
the LDL receptor (LDLR) and familial hypercholesterolemia
(FH). Similarly, the genes encoding Kir6.2, WFS1, and
TCF2 are all known to cause Mendelian syndromes
including type 2 diabetes, as well as common SNPs
with modest effects.
7.
Because allele frequencies vary across human
populations, the relative roles of common
susceptibility genes can vary among ethnic groups. One
example is the association of prostate cancer at
8q24: SNPs in the region play a role in all ethnic groups,
but the contribution is greater in African Americans.
This is not because the risk alleles yet found
confer greater susceptibility in African Americans, but
because they occur at higher frequencies, contributing
to the higher incidence among African American men than among
men of European ancestry.
|