Nucleic acids
As a class, the nucleotides may be
considered one of the most important metabolites of the cell.
Nucleotides are found primarily as the monomeric units
comprising the major nucleic acids of the cell, RNA and DNA.
However, they also are required for numerous other important
functions within the cell. These functions include:
1. serving
as energy stores for future use in phosphate transfer reactions.
These reactions are predominantly carried out by ATP.
2. forming
a portion of several important coenzymes such as NAD+,
NADP+, FAD and coenzyme A.
3. serving
as mediators of numerous important cellular processes such as
second messengers in signal transduction events. The predominant
second messenger is cyclic-AMP (cAMP), a cyclic derivative of
AMP formed from ATP.
4.
controlling numerous enzymatic reactions through allosteric
effects on enzyme activity.
5. serving
as activated intermediates in numerous biosynthetic reactions.
These activated intermediates include S-adenosylmethionine (S-AdoMet
or SAM) involved in methyl transfer reactions as well as the
many sugar coupled nucleotides involved in
glycogen and
glycoprotein synthesis.
Nucleoside and nucleotide structure and
nomenclature
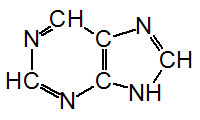
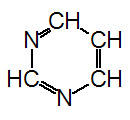
The nucleotides found in cells are
derivatives of the heterocyclic highly basic compounds purine
and pyrimidine.
 |
 |
Purine
|
Pyrimidine
|
It is the chemical basicity of the
nucleotides that has given them the common term "bases" as they
are associated with nucleotides present in DNA and RNA. There
are five major bases found in cells. The derivatives of purine
are called adenine and guanine, and the derivatives of
pyrimidine are called thymine, cytosine and uracil. The common
abbreviations used for these five bases are, A, G, T, C and U.
| Base Formula |
Base (X=H) |
Nucleoside
X=ribose or deoxyribose |
Nucleotide
X=ribose phosphate |
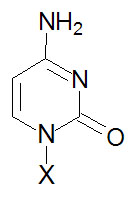 |
Cytosine, C |
Cytidine, C |
Cytidine monophosphate, CMP |
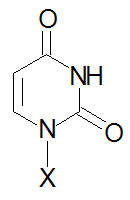 |
Uracil, U |
Uridine, U |
Uridine monophosphate, UMP |
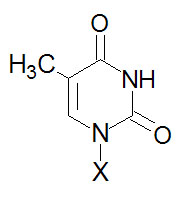 |
Thymine, T |
Thymidine, T (only
deoxyribose) |
Thymidine monophosphate, TMP |
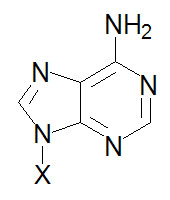 |
Adenine, A |
Adenosine, A |
Adenosine monophosphate, AMP |
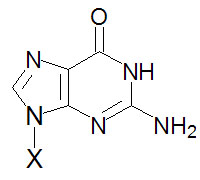 |
Guanine, G |
Guanosine, G |
Guanosine monophosphate, GMP |
The purine and pyrimidine bases in cells
are linked to carbohydrate and in this form are termed,
nucleosides. Nucleosides are found in the cell
primarily in their phosphorylated form. These are termed
nucleotides. The most common site of phosphorylation of
nucleotides found in cells is the hydroxyl group attached to the
5'-carbon of the ribose The carbon atoms of the ribose present
in nucleotides are designated with a prime (')
mark to distinguish them from the backbone numbering in the
bases. Nucleotides can exist in the mono-, di-, or
tri-phosphorylated forms.
Nucleotides are given distinct
abbreviations to allow easy identification of their structure
and state of phosphorylation. The monophosphorylated form of
adenosine (adenosine-5'-monophosphate) is written as, AMP. The
di- and tri-phosphorylated forms are written as, ADP and ATP,
respectively. The use of these abbreviations assumes that the
nucleotide is in the 5'-phosphorylated form. The nucleotides found in DNA are unique
from those of RNA in that the ribose exists in the 2'-deoxy form
and the abbreviations of the nucleotides contain a "d"
designation. The monophosphorylated form of adenosine found in
DNA (deoxyadenosine-5'-monophosphate) is written as dAMP.
The nucleotide uridine is never found in
DNA and thymine is almost exclusively found in DNA. Thymine is
found in tRNAs but not rRNAs nor mRNAs. There are several less
common bases found in DNA and RNA. The primary modified base in
DNA is 5-methylcytosine. A variety of modified bases appear in
the tRNAs. Many modified nucleotides are encountered outside of
the context of DNA and RNA that serve important biological
functions.
Adenosine derivatives
The most common adenosine derivative is
the cyclic form, 3'-5'-cyclic adenosine monophosphate,
cAMP. This compound is a very powerful second messenger
involved in passing
signal transduction events from the cell surface to internal
proteins, e.g. cAMP-dependent protein kinase,
PKA. PKA phosphorylates a number of proteins,
thereby, affecting their activity either positively or
negatively. Cyclic-AMP is also involved in the regulation of ion
channels by direct interaction with the channel proteins, e.g.
in the activation of odorant receptors by odorant molecules. Formation of cAMP occurs in response to
activation of receptor-coupled adenylate cyclase. These
receptors can be of any type, e.g. hormone receptors or odorant
receptors.
Guanosine derivatives
A cyclic form of GMP (cGMP) also is found
in cells involved as a second messenger molecule. In many cases
its' role is to antagonize the effects of cAMP. Formation of
cGMP occurs in response to receptor mediated signals similar to
those for activation of adenylate cyclase. However, in this case
it is guanylate cyclase that is coupled to the receptor. The most important cGMP coupled signal
transduction cascade is that
photoreception. However, in this case activation of
rhodopsin (in the rods) or other opsins (in the cones) by the
absorption of a photon of light (through 11-cis-retinal
covalently associated with rhodopsin and opsins) activates
transducin which in turn activates a cGMP specific
phosphodiesterase that hydrolyzes cGMP to GMP. This lowers the
effective concentration of cGMP bound to gated ion channels
resulting in their closure and a concomitant hyperpolarization
of the cell.
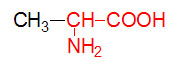
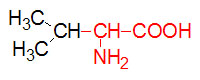
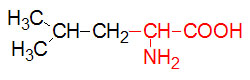
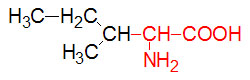
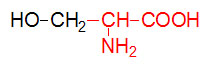
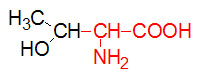
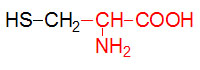
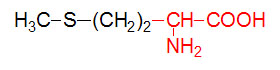

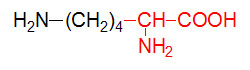
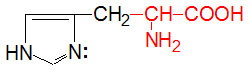
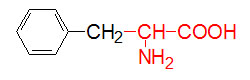
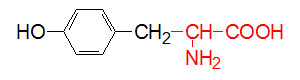
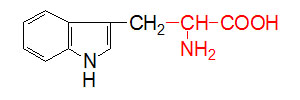
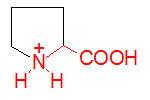
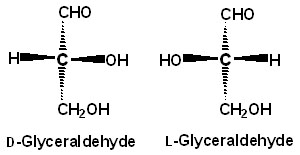
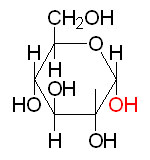 α-D-Glucose
α-D-Glucose
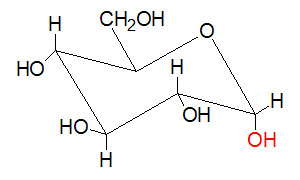 Chair form of α-D-Glucose
Chair form of α-D-Glucose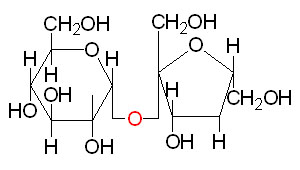 Sucrose
Sucrose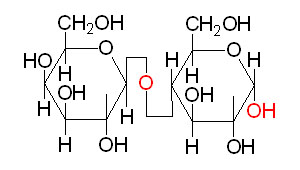 Lactose
Lactose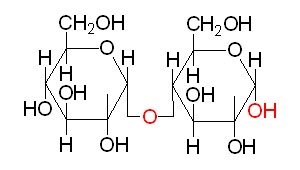 Maltose
Maltose 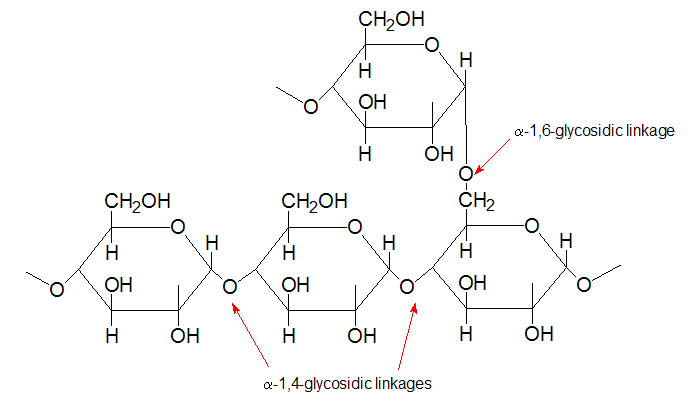 Section of
glycogen showing α–1,4– and α–1,6–glycosidic linkages
Section of
glycogen showing α–1,4– and α–1,6–glycosidic linkages Palmitic
acid
Palmitic
acid






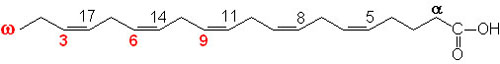

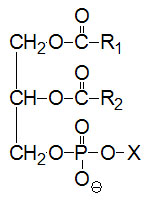 Basic composition of a
phospholipid.
X can be a number of different substituents.
Basic composition of a
phospholipid.
X can be a number of different substituents.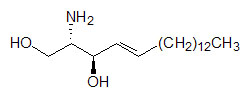 Sphingosine
Sphingosine Basic composition of a ceramide
Basic composition of a ceramide