|
MOLECULAR & CELLULAR
NEUROBIOLOGY - NEUROGENOMICS
Master Course Cognitive Neuroscience - Radboud
University, Nijmegen
Chapter 5: Molecular biology and genetics |
| The human genome & HapMap projects | Animal disease models | |
| The evolution of molecular biology | Genetic transmission | Polygenic diseases |
| Understanding DNA | Genetic mapping |
Understanding DNA: the molecule of life |
|
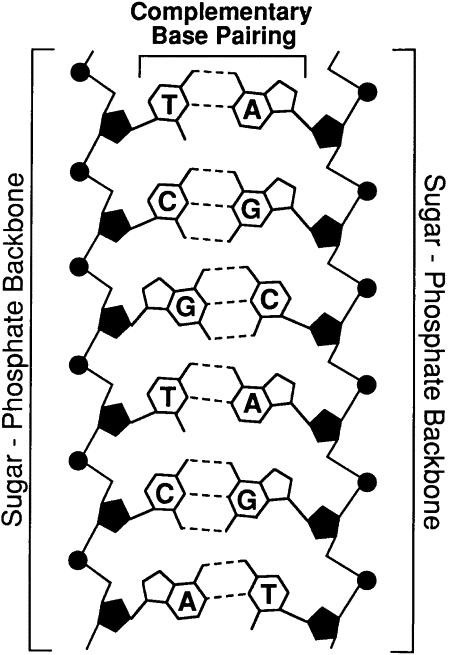
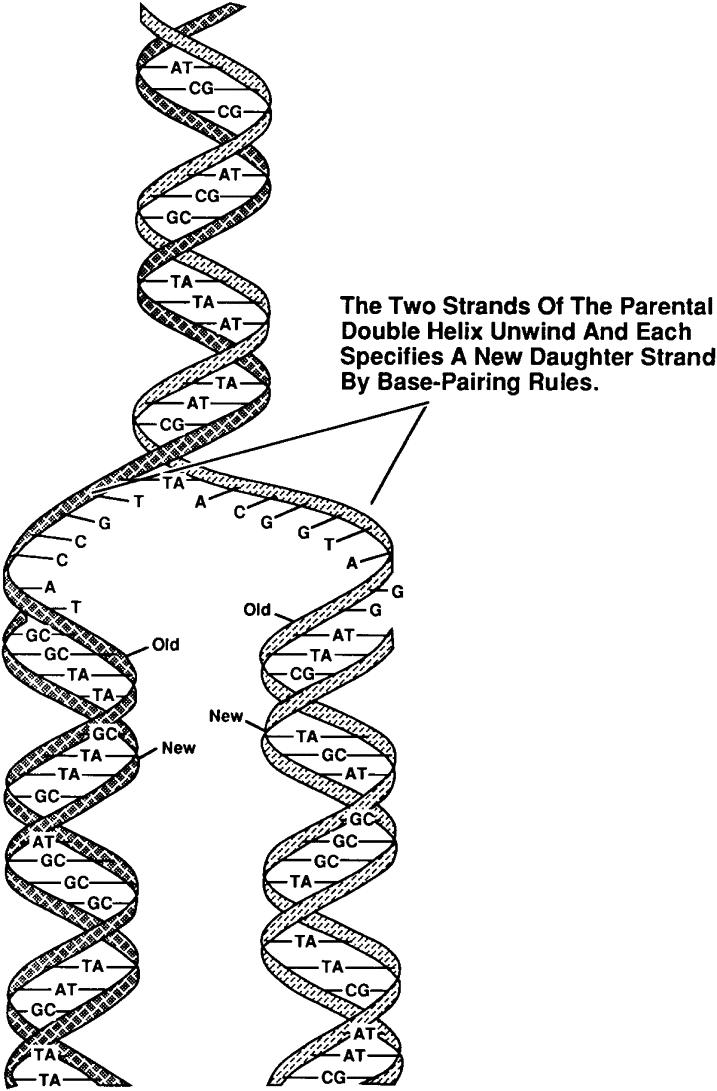
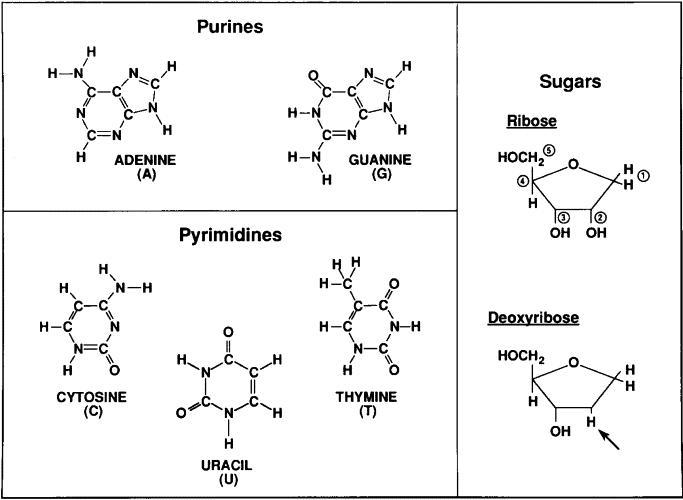
The DNA molecule is a linear polynucleotide consisting of repeating units of nucleotides. Each nucleotide consists of one base, a deoxyribose sugar, and a phosphate molecule. There are four bases: adenine, cytosine, guanine, and thymine. Adenine and guanine are purines and cytosine and thymine are pyrimidine bases. Each base is bound to one sugar and one phosphorous molecule. The ribose molecule lacks a hydroxyl group (OH) at the number 2 carbon on the ring and thus the designation deoxyribonucleic acid. The purine bases (adenine and quanine) are two-ringed structures and the pyrimidine bases (thymidine and cytosine) are the single-ringed structures (Fig 1). The double-helix structure arises from the complementary pairing between the purine base of one strand and the pyrimidine base of the second strand. The complementary pairing is optimally stabilized by hydrogen bonds formed between the purine and the pyrimidine base, such that guanine (G) will always pair with cytosine (C) via three hydrogen bonds and adenine (A) will always pair with thymidine (T) via two hydrogen bonds (Fig 2). Because of incompatible ring conformations, cross pairing between the other purines and pyrimidines, ie, adenine with guanine and cytosine with thymine, do not occur. This complementary base pairing is the basis of molecular genetics. The binding of a phosphorus molecule to each nucleoside gives rise to a nucleotide. When each nucleotide strand is considered individually, the sequence of nucleotide bases is always read from left to right from the 5′ carbon to 3′ carbon direction (Fig 3). In the double-helix configuration, the strand complementary to the 5′ to 3′ strand is oriented in a 3′ to 5′ direction relative to its complementary strand. This organization is referred to as the antiparallel or antisense arrangement of the DNA strands. For example, nucleotide pairing between a nucleotide strand with a 5′ ATCCG 3′ sequence has as its complementary strand 3′ TAGGC 5′ in the double-helix configuration. Additionally, when describing segments of DNA, it is common to refer to them by size. For example, a segment of double-stranded DNA composed of 200 nucleotides is often referred to as a 200-basepair (bp) segment. Similarly, 1000- and 1,000,000-nucleotide segments are 1-kb or 1000-kbp [1-megabase (Mb)] segments. See also under DNA and genes and More on DNA. |
|
FIG 1. Building blocks of nucleic acids, DNA comprises a deoxyribose sugar backbone with the nucleotide bases adenine, guanine, cytosine, and thymidine attached to the C1 position carbon on the sugar ring.
|
|
|
|
FIG
2. Specificity of DNA basepairing. The two strands of DNA are bound together via
hydrogen bonds between the nucleotide bases on each strand. The bonds are formed
by strict pairing between two complementary bases, A
|
|
|
|
FIG 3. DNA replication conserves the nucleotide sequence. DNA is a double-stranded helical molecule bound together by the nucleotide bases contained on each individual strand. During cell division, two identical copies of the original parental strand are made by unwinding the DNA and then synthesizing a complementary second strand to make two identical new daughter stands. Source: Roberts R. Essentials of nucleic acids and proteins.
|
|
The genome refers to the complete DNA sequence of an organism, which is enclosed in the nucleus of a cell (Table 2). In the human, there are 3 billion base pairs, which contain information that would more than fill a 500,000-page textbook. It is estimated that, in a single individual, if all of the chromosomes were joined end to end, it would reach from the earth to the moon about 8000 times. The actual length of the DNA from each cell is not apparent because the DNA helix of each chromosome exists as a compact, coiled structure stabilized by protein molecules, many of which are histones. The compact nature results in an increase in diameter, thus allowing the DNA to be visible by electron microscopy. The coiled, compact character of DNA enables all of the genetic information from a single cell to fit neatly into the cell’s nucleus, which occupies less than 10% of the total cell volume. The 22-25,000 genes encoding a human being accounts for about 1% of the DNA, thus most of the DNA is noncoding. There are 46 chromosomes, and each chromosome is a long continuous DNA molecule. The chromosomes vary in size, but even chromosome 21, the smallest of them, contains more than 50,000,000 base pairs. |
Table 2. The human genome (completed April 2003)
|
Number of bases |
3.2 billion |
|
Genes estimated |
25,000 |
|
DNA for genes |
1.5% |
|
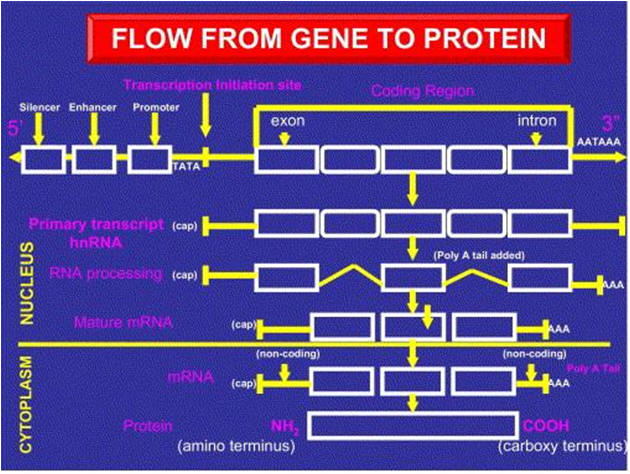
The definition of a gene A gene is a distinct segment of the DNA forming a chromosome that has the appropriate DNA sequences promoting transcription to mRNA, and coding sequences to be transcribed and subsequently translated into a single polypeptide (Fig 4). Typically, we think of a gene as having the 5′ ends, which is not transcribed but is recognized by proteins that initiate the transcription process, followed by the protein-coding sequence and the 3′ ends for stability. The coding sequence is referred to as the reading frame that starts with an ATG triplet, followed by various arrangements of triplet bases (codons), which specify the amino acids to form a polypeptide. The 3′ end of the gene is not translated into protein but is transcribed to impart stability to the messenger RNA. The codons TGA, or TAA or TAG (triplet stop codon), found at end of the reading frame, terminate the reading frame for amino acids. The protein coding sequences (exons) for proteins are separated by noncoding sequences (introns), with the latter spliced out during the transcription process and excluded from the mRNA. The exon–intron boundaries have characteristic sequences, beginning with GT and ending with AG. Among the billion of bases of DNA, these sequence characteristics enable computer algorithms to predict which segments of DNA contain genes coding for protein. The gene requires many proteins to initiate and promote transcription (transcription factors) including enhancers and silencers (Fig 5). Transcription is usually initiated about 32 nucleotides upstream from the starting codon of ATG at a sequence referred to as the TATA box.
|
|
|
|
FIG 4. Regulation of gene activation. Schematic of the components of gene structure that contributes to gene activation and protein synthesis. RNA polymerase binds to a site at the beginning of a gene0 (promoter region) that often contains a TATA box. Other gene elements (enhancers) may regulate this process. A heteronuclear RNA copy of the gene (hnRNA) is produced that contains protein coding (exons) and noncoding (introns) sequences. The noncoding introns are spliced out and the RNA is “capped” at the 5′ end and polyadenylated at the 3′ end [poly(A) tail] to form a mature messenger RNA (mRNA). The mRNA is used to synthesize the protein encoded for by this gene in the cell cytoplasm.
|
|
|
|
FIG 5. Types of transcription factors which affect gene activation. Schematic representation of the shape of four types of protein transcription factors that bond to DNA and influence gene activation. Helix-turn-helix is a protein with two alpha-helices separated by a beta-turn. Leucine zippers are protein dimers with interdigitating leucine amino acids. Zinc fingers have a peptide loop connected at the base by a zinc ion tetrahedron between cysteine and/or histidine in amino acids. The helix-loop-helix consists of beta-helix but utilizes leucine zippers and has a loop between the beta-helices. The darkened areas are believed to be the regions of the protein that interact with the DNA to modulate transcription. |
| Next page: The human genome & HapMap projects | Go back to: The evolution of molecular biology |